Inverse Painting: Reconstructing The Painting Process
SIGGRAPH Asia 2024

Abstract
Given an input painting, we reconstruct a time-lapse video of how it may have been painted. We formulate this as an autoregressive image generation problem, in which an initially blank "canvas" is iteratively updated. The model learns from real artists by training on many painting videos. Our approach incorporates text and region understanding to define a set of painting ``instructions'' and updates the canvas with a novel diffusion-based renderer. The method extrapolates beyond the limited, acrylic style paintings on which it has been trained, showing plausible results for a wide range of artistic styles and genres.
Video
Our Pipeline
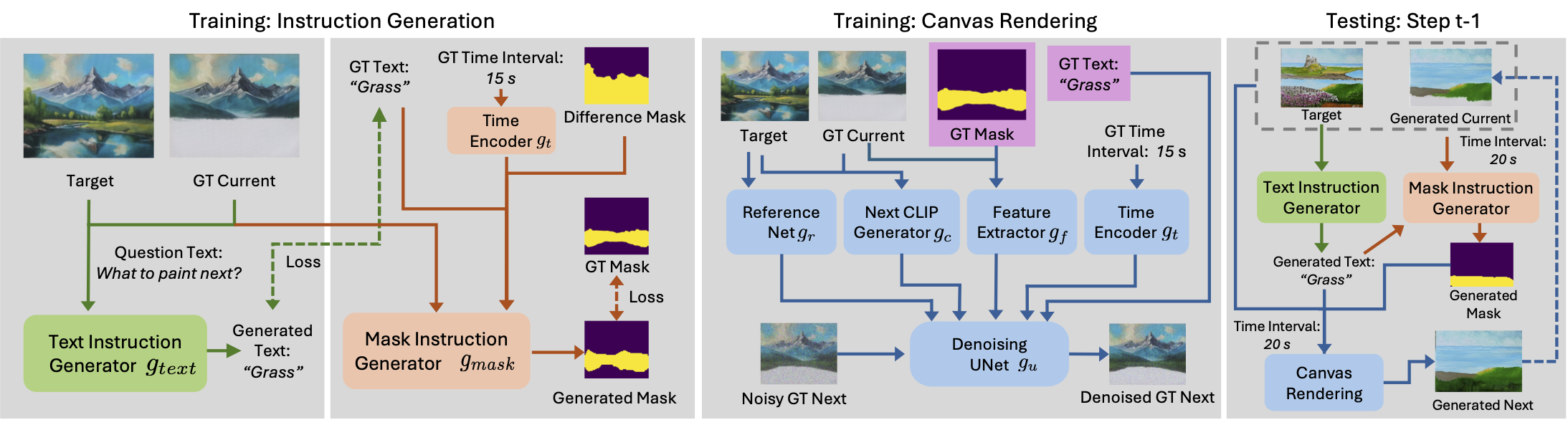
The training has two stages. The instruction generation stage (left two gray boxes) includes the text instruction generator (green) and the mask instruction generator (light orange). These generators produce the text and mask instructions essential for updating the canvas in the next stage. The second stage is canvas rendering (third gray box), where a diffusion-based renderer generates the next image based on multiple conditional signals, such as text and mask instructions. To simplify the figure, we omit the VAE encoder, CLIP encoder, and text encoder. During testing at step $t-1$ (last gray box), we first generate a text instruction (green arrows), which is then used to create a region mask (orange arrows). Both are then provided to the canvas rendering stage to produce the next image (blue arrows). Image courtesy Catherine Kay Greenup.
Our Results

Input Painting
Outputs

Input Painting
Outputs

Input Painting
Outputs

Input Painting
Outputs

Input Painting
Outputs

Input Painting
Outputs
Images courtesy Catherine Kay Greenup, National Gallery of Art, Washington, and Rawpixel.
Baseline Comparison

Input Painting
GT
Ours
Timecraft
Paint Transformer
Stable Video Diffusion
Acknowledgements
Special thanks to Zi Lin for her constructive feedback and help in data collection; Yuqun Wu, Tianyuan Zhang, Meng-Li Shih, and Mengyi Shan for their help in proofreading the paper; and Xinyi Liu, Linning Xu, Xuan Luo, and Zi Lin for their valuable insights on the painting process.
This work was supported by the UW Reality Lab and Google.